Top 10 Security Tips for a New Real Estate Website
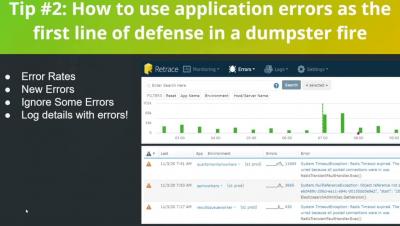
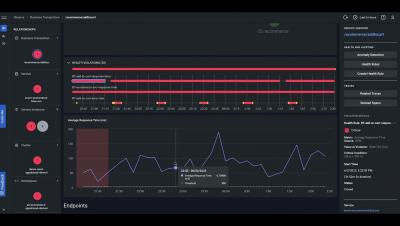
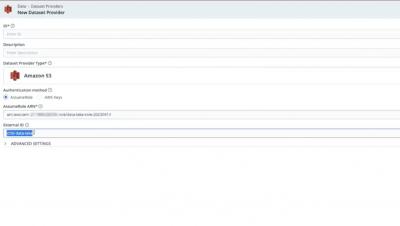
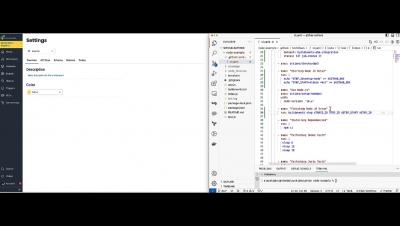
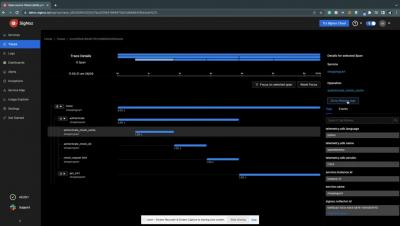
As the real estate industry embraces digitalisation, establishing a secure online presence has become essential for real estate websites. Protecting sensitive data, ensuring user privacy, and maintaining a trusted online reputation are crucial for the success of your real estate website. This article discusses the top 10 security tips for safeguarding your new real estate website.