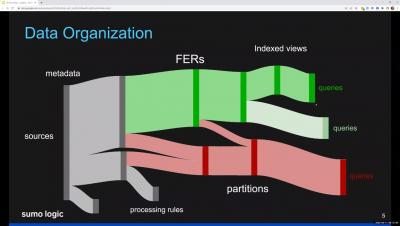
Cloud Capacity Planning Is a Hit-or-Miss Exercise That Mostly Misses
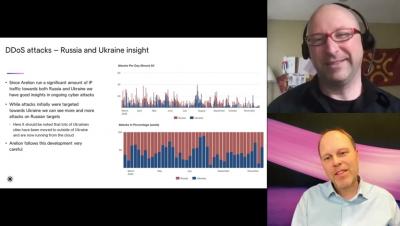
The goal of capacity planning is to match resources with demand. There are essentially three outcomes from this analysis. You can underestimate the resources you need (underprovision), which can hurt performance. You can overestimate (overprovision), which adds unnecessary costs. Or you can get it just right (rightsized). And, of course, you want to be rightsized at the lowest possible cost. Because many factors go into cloud capacity planning, it can feel like more of an art than a science.