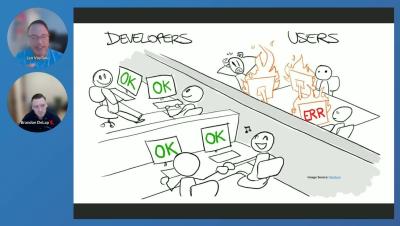
GenOps: learning from the world of microservices and traditional DevOps
GenOps is a new operational platform for Generative AI. Learn the difference between AI agents and microservices and how to implement GenOps.


Try Sentry for free: https://sentry.io
Docs: https://docs.sentry.io
Follow: https://twitter.com/getsentry
Try Sentry for free: https://sentry.io
Docs: https://docs.sentry.io
Follow: https://twitter.com/getsentry