What is DNS monitoring? How it helps improve the performance of your network services
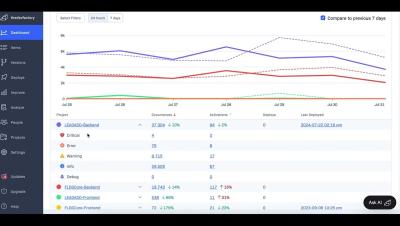
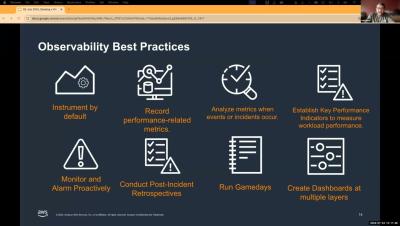
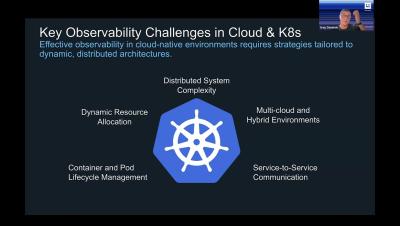
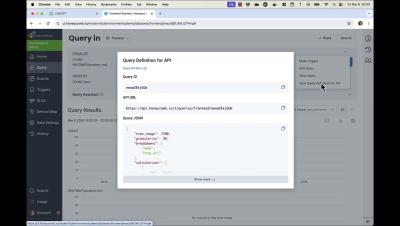
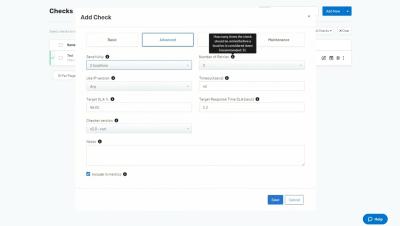
DNS service management tools are currently considered a crucial element by many organizations, as they simplify the administration and issue detecting activities for admins. Along with streamlining DNS service for elevating organization’s network service for clients. Despite managing and automating DNS activities across different DNS service providers, every DNS tool has one key feature that every organization rely on: DNS monitoring.