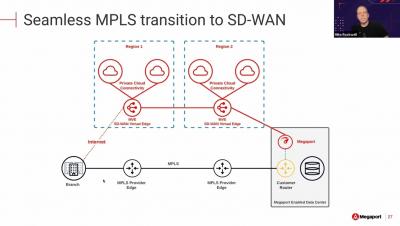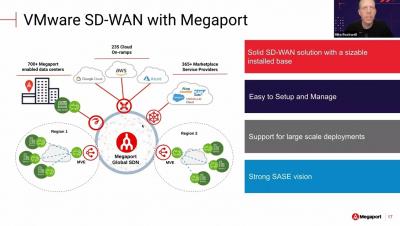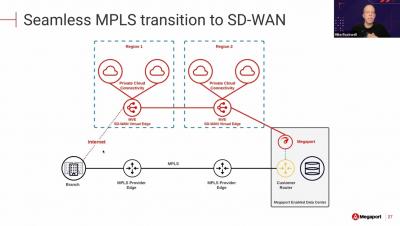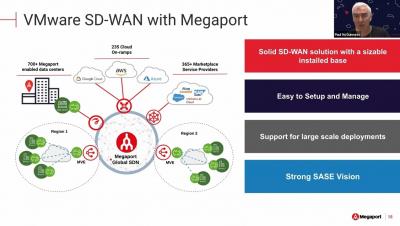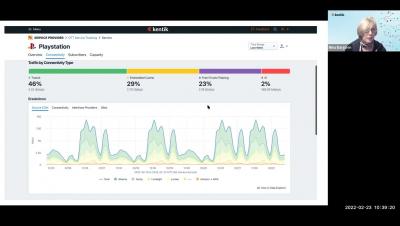
The NetOps Expert - Episode 5: Broadcom Software and AppNeta - Part 2
Jeremy Rossbach, Head of DX NetOps Product Marketing and Alec Pinkham, Head of AppNeta Product Marketing continue their discussions on the recent acquisition of AppNeta by Broadcom and the reasons why the combination of both network monitoring solutions sets it apart from the industry and why our customers should be excited for the future of their network visibility.