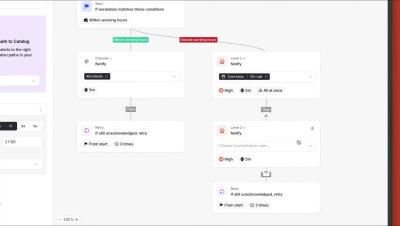
Year in Review: How Squadcast Transformed Incident Management in 2024
As 2024 draws to a close, we’re excited to reflect on a year filled with innovation, customer success, and continuous improvements at Squadcast. From game-changing feature releases to remarkable customer achievements, this has been a year of progress and transformation. In this blog, we’ll walk you through everything that made 2024 a standout year for Squadcast.