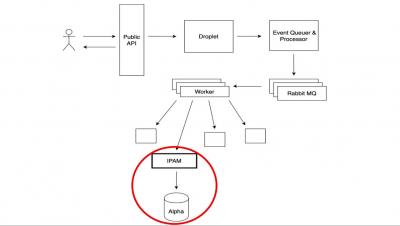
Master Class - PCI Compliance and Vulnerability Management for Kubernetes - 2020-05-05
This is the Rancher Master Class with NeuVector that was held on May 5, 2020. In it NeuVector talks about the challenges with PCI-DSS compliance when working with Kubernetes and presents strategies for securing containers and content, both using OSS tools and with their paid solutions.