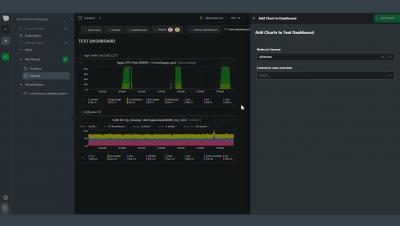
Learn how to build interactive dashboards with Netdata Cloud for troubleshooting systems
This video will show you how to build new dashboards with key metrics from any number of distributed systems in one place for a bird's eye view of your infrastructure. Create more meaningful visualizations for troubleshooting or keep a watchful eye on your infrastructure's most meaningful metrics without moving from node to node. Netdata’s free, open-source monitoring agent works with Netdata Cloud to help you monitor and troubleshoot every layer of your systems to find weaknesses before they turn into outages.