Operations | Monitoring | ITSM | DevOps | Cloud


The latest News and Information on Incident Management, On-Call, Incident Response and related technologies.

The Dangers of Alert Fatigue: Strategies for Effective Alert Management
Alert fatigue is a serious issue that affects numerous professions, especially in the IT industry. It can lead to neglecting critical events and delaying response times. IT teams need to continuously monitor their systems and applications to avert possible downtime and keep operations running smoothly. However a high number of incoming alerts inundating these teams can make them less responsive. The ramifications of such disregard can severely affect the efficiency and dependability of IT teams.

User story: How a global media company reduced costly outages by implementing a secure DevSecOps collaboration platform
Catastrophic failures — such as a security breach or a complete outage leading to an unavailable product or service — are classified as Sev0 incidents. On a severity scale of 1–3, Sev0 is dire. It brings business to a complete standstill and may lead to loss of revenue and a damaged reputation. A Sev0 incident usually has no quick workaround; it requires a coordinated effort beyond the engineering team to diagnose, correct, and manage.

Welcome To xMatters - Ep 1 - Connecting Your Tools

MTTR, MTTA, SLA... What's the Difference?
These abbreviations are used often in the world of DevOps, NOC, and R&D, but often they are used interchangeably when they aren't actually the same. So, what's the difference?
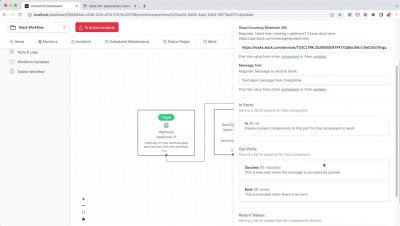
Connect Slack to OneUptime using Workflows

Should Every Incident Get a Retro?
At a recent training session, Jeli spent a great deal of time covering incident retrospectives and what makes an incident worthy of studying. My colleague Ben Hartshorne asked a fascinating question, which I’ll paraphrase here: That caught me by surprise. We had a great discussion, and it made me consider approaches I hadn’t before.

Identify & Resolve IT Infrastructure Incidents

9 incident management solutions to improve your workflows
Incident management is a team effort. While it's true that incident management should be seen as a company-wide effort, and you should empower all teams to declare incidents, this differs from the team effort I'm referring to here. No, incident management is a team effort in the sense that no one tool can do it all, not even incident.io. We covered as much when we discussed why we integrate with tools that can be seen as our competitors – and that’s OK!

8 Best IT Monitoring Tools and Software of 2023 (Updated)
Monitoring tools, also known as observability solutions, are designed to track the status of critical IT applications, networks, infrastructures, websites and more. The best IT monitoring tools quickly detect problems in resources and alert the right respondents to resolve critical issues. Response teams use observability solutions to gain real-time insights into resource availability, stability and performance.