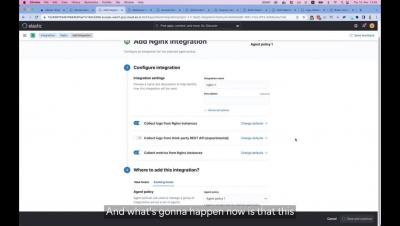
Ingesting and managing your Nginx Logs in Elastic
Learn how to ingest Nginx logs using Elastic agent and nginx integration and view metrics in OOTB dashboards.


The latest News and Information on Log Management, Log Analytics and related technologies.
If the past year has taught us anything, it’s that the more things change, the more things stay the same. The whiplash and pivot from the go-go economy post-pandemic to a belt-tightening macroeconomic environment induced by higher inflation and interest rates has been seen before, but rarely this quickly. Technology leaders have always had to do more with less, but this slowdown may be unpredictable, longer, and more pronounced than expected.
We're excited to announce AppSignal Log Management, a straightforward solution for ingesting and analyzing your logs. AppSignal is designed to be intuitive and help you get the most out of your application's monitoring data. Here's what you'll get with our logging solution.
Prometheus is the de facto open-source solution for collecting and monitoring metrics data. Its straightforward architecture, operational reliability, minimal upfront cost, and versatility in integrating with cloud-native systems make it the preferred choice for many. Getting started is as simple as configuring the Prometheus server and setting simple parameters such as the scrape intervals and targets, cadence, and setting the job name based on the function of the server.








