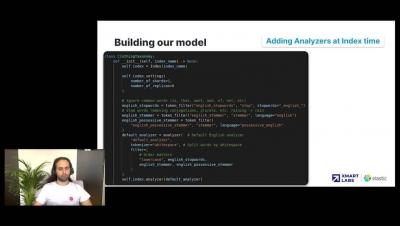
Finding matches when using a taxonomy is a common problem. A notable challenge is mapping a user’s query to the entity (or results) expected when searching for an entity inside a catalog mapping. Functional textual search models tend to rely on exact match or partial match, but both can lead to a frustrating experience when users aren’t familiar with the domain. Basic models often fail to support user typos, synonyms, acronyms, and/or hyponyms/hypernyms. Learn how to tackle these challenges and make search more intuitive when using a taxonomy.