

Experience-Driven NetOps: The Integration of AppNeta and DX NetOps
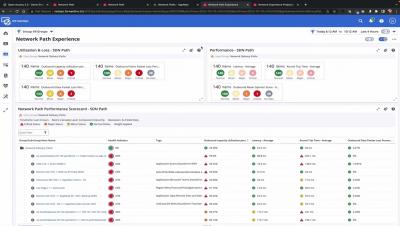
AppNeta and DX NetOps enable Experience-Driven NetOps by bringing user experience and visibility across both managed and unmanaged networks into a unified console. Start with alarms and drill down to see the details of performance along the complete network path, hop by hop, including information about voice and data to understand issues over time. Use dashboards to see insights into the health of your network delivery paths across your organization and drill-in to isolate the problem with detailed reports including network experience capacity projections for ISPs.








