Interrupts in software teams: using unplanned work to your advantage
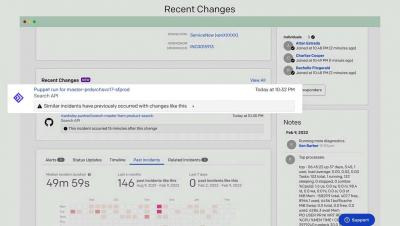
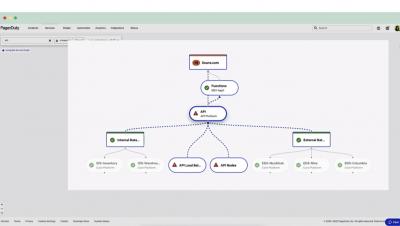
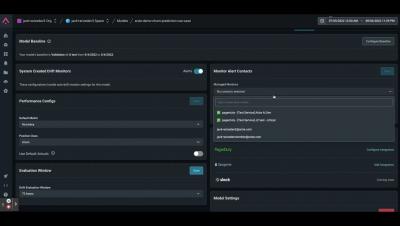
Interrupts are often seen as a problem that eats away at your team’s productivity, and gets in the way of shipping important things for your customers. It’s often consciously accrued from the tech debt we accept to ship features sooner. However when a team doesn’t have a good strategy for dealing with the consequences of those decisions, the pain is felt much more acutely and much sooner.