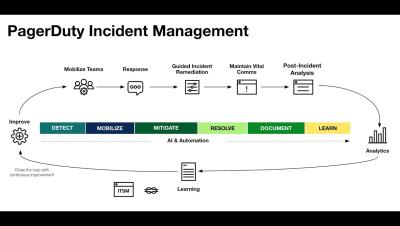
The Role of the SRE in the Incident Management Process
In the world of modern businesses, where IT systems play a major role in all types of businesses, the role of the Site Reliability Engineer (SRE) has become central to managing the effectiveness and reliability of the entire business. SREs are the bridge between the rapid deployment of software and systems and the stable operation of those systems in a production environment. They ensure that reliability and performance criteria are defined and are met.