

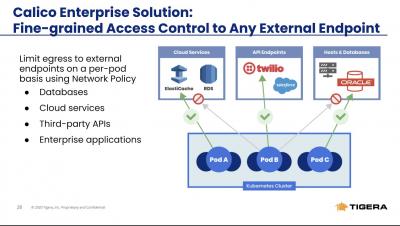
Kubernetes Access Controls with Calico Enterprise - How to apply egress access controls
No matter where you are in your Kubernetes journey, eventually you’ll have to connect your k8s cluster to external resources like databases, cloud services, and third-party APIs. A majority of existing workloads are non-Kubernetes, and at some point, your Kubernetes applications will need to communicate with them.








