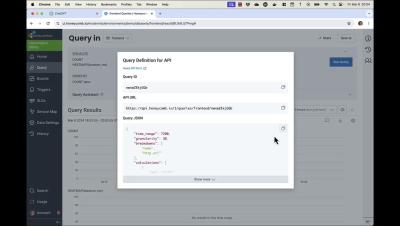
Application observability: Maximizing uptime and performance
In this blog post, we'll dive into the critical role of application observability in maintaining optimal performance and uptime. We'll explore how it works, why it's essential, and how it transforms challenges into opportunities for growth and improvement. So, if you're looking to elevate your application's performance and reliability to new heights, you're in the right place.