

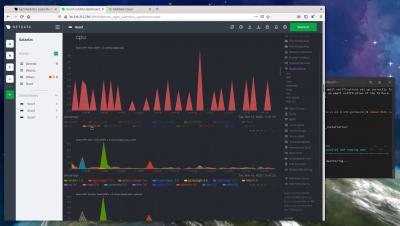
Go from 0 to monitoring in minutes with Netdata
Netdata is zero-configuration monitoring. It’s a principle that we’ve stood behind since the project’s beginning, when it was only our CEO Costa trying to solve a “painful, real-world problem,” and it’s one we stand by today. Our insistence on zero-configuration guides every product decision we make, every grooming process, and every React component our frontend teams design.








