

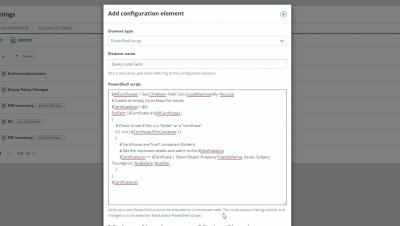
How to Monitor Changes to Local Certificates
Local certificates provide a multitude of security benefits. From encrypting emails and allowing easier authentication, to securing connections between web browsers and your web servers, they're a necessary part of any network. Learn how to monitor changes to local certificates with SolarWinds® Server Configuration Monitor.








