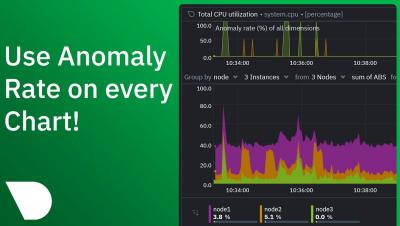
Using Cribl Search for Anomaly Detection: Finding Statistical Outliers in Host CPU Busy Percentage
In this blog post, we’ll demonstrate how to use Cribl Search for anomaly detection by finding statistical outliers in host CPU usage. By monitoring the “CPU Busy” metric, we can identify unusual spikes that may indicate malware penetration or high load/limiting conditions on customer-facing hosts. The best part? This simple but powerful analytic is easily adaptable to other metrics, making it a versatile tool for any data-driven organization.