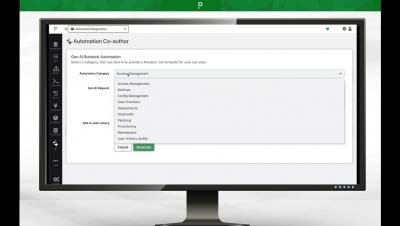
GenAI Innovation: Process Automation
PagerDuty announces a new Generative AI-powered use case on the Operations Cloud platform: Process Automation.


The latest News and Information on Incident Management, On-Call, Incident Response and related technologies.
When it comes to keeping your business’s lights on, you need to manage and orchestrate your operational activities, prioritize high-impact and urgent work, and maintain day-to-day precision. Trust is paramount during mission-critical, time-sensitive crisis response and the narrow margin for error means there is little room and low acceptance for generative AI hallucinations or false positives.
The first moments of incident response can be among the most crucial, which in turn can also make them among the most stressful. There are many ways to ensure incidents are kicked off smoothly, but a recent focus of ours was to ensure they could be kicked off quickly. After all, the faster you're able to start mitigating your incident, the more successful you'll be!
When our CEO and co-founder Tomer Levy delivered his “Observability is Broken” presentation at last year’s AWS re:Invent, he highlighted numerous challenges faced by today’s organizations as they seek to advance their observability practices. Of the six individual points that he noted, two specifically dealt with the current shortage of available engineering expertise, with another two focused on data overload.
Although the causes and solutions for incidents vary widely, most incidents follow a similar timeline from declaration to resolution. We call the period of time it takes to move from one phase or milestone of an incident to the next cycle time.








