Welcome to StatusCast Demo Video!
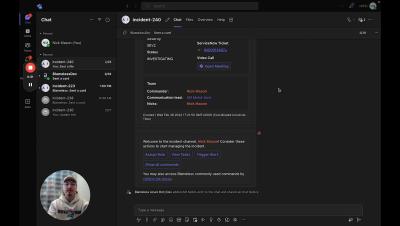
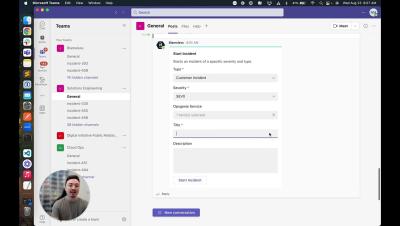
Welcome to the StatusCast Demo Video – Your Ultimate Guide to Seamless Status Communication! 🚀 About StatusCast: StatusCast is a cutting-edge platform designed to revolutionize the way you communicate service status and incidents to your users. Whether you're a tech company, SaaS provider, or any organization relying on online services, StatusCast ensures that you keep your users informed, engaged, and satisfied.