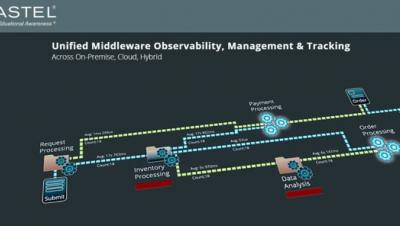
An introduction to using Nastel with Amazon MSK
Nastel MSK is an option for using Apache Kafka. This introduction explains the basics of Amazon MSK and the show how in just a matter of minutes, you can be using Nastel to manage, monitor and track your Kafka usage.