timeShift(GrafanaBuzz, 1w) Issue 72
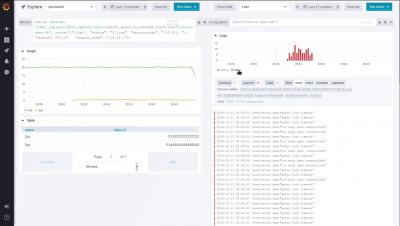
The Grafana Labs team converged on Seattle this week for KubeCon + CloudNativeCon NA 2018 where we announced a new Prometheus-inspired, open source logging project we’ve been working on named Loki. We’ve been overwhelmed by the positive response and conversations it’s sparked over the past few days. Please give it a try on-prem or in the cloud and give us your feedback. You can read more about the project, our motivations, and check out the presentation in the blog section below.