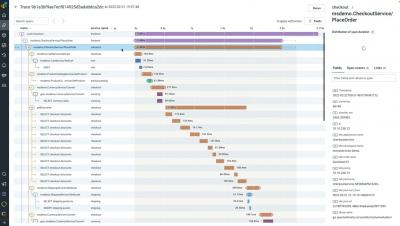
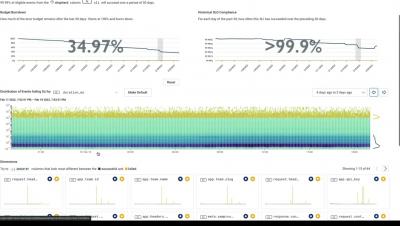
Uptrace distributed tracing tool
Uptrace is an OpenTelemetry tracing tool that monitors performance, errors, and logs
https://get.uptrace.dev/


The latest News and Information on Observabilty for complex systems and related technologies.
Uptrace is an OpenTelemetry tracing tool that monitors performance, errors, and logs
https://get.uptrace.dev/
It’s common sense. When a logstorm hits, you don’t want to be left scrambling to find the one engineer from each team in your organization that actually understands the logging system – then spending even more time mapping the logging format of each team with the formats of every other team, all before you can begin to respond to the incident at hand. It’s a model that simply won’t scale.
Honeycomb Pro is about to get even better. Starting today, all Pro accounts have access to Honeycomb Metrics and two Service Level Objectives (SLOs), previously only available to Enterprise accounts. Full disclosure: Later this month, the price of Pro plans will be increasing as well (see below). However, existing Pro customers (including those that sign up before the new pricing goes into effect) will be able to enjoy the new capabilities at existing prices for a full year, until April 2023!
I don’t care about religious wars over “which logger is the best”. They all have their issues. Having said that, the worst logger is probably the one built “in-house”… So yes, they suck, but re-inventing the wheel is probably far worse. Let’s discuss making these loggers suck less with proper usage guidelines that range from the obvious to subtle. Hopefully, you can use this post as the basis of your company’s standard for logging best practices.
When IT operators and architects begin their journey with Google Cloud, Day 0 observability needs tend to focus on infrastructure and aim to address questions about resource needs, a plan for scaling, and similar considerations. During this phase, developers and DevOps engineers also make a plan for how to get deep observability into the performance of third-party and open-source applications running on their Compute Engine VMs.
The one certainty you will find in IT, developer, and SRE roles is that things always change! One hot topic in DevOps communities is observability. A long word, you may be wondering what it really means and how you can add it to your skillset. Here’s a quick primer to get you going on your path to observability.
Managing the complexities of today’s cloud native infrastructure has resulted in the increased need for observability. As cloud adoption continues to grow, the need to deliver a better customer experience, scale efficiently and increase momentum on innovation has never been more important. For many organizations to carry out these principles, two technologies are helping organizations deliver on these goals faster: Monitoring-as-Code and Infrastructure-as-Code.