Make your ITSM more efficient with PagerDuty and ServiceNow
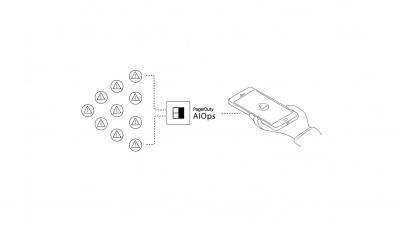
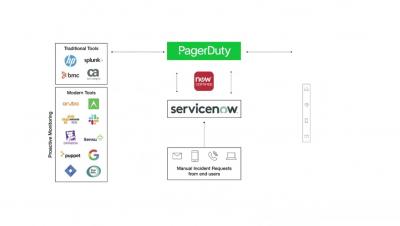
Putting PagerDuty between your monitoring systems, CI/CD systems—really, anything emitting events about your digital environment— and your ServiceNow CMDB opens the door for better event management and correlation, incident response automation, advanced analytics and more, helping you service distributed and central teams together for faster turnaround and better customer experience.