

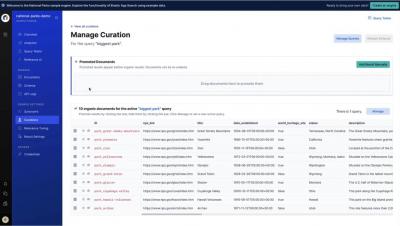
How to define curation in Elastic App Search
Want certain information to appear at the top of search results? When you add curations in App Search, users get the promoted documents first, then the most relevant results based on the relevance tuning you defined. In this short video, you’ll learn how to set up curation in Elastic App Search.








