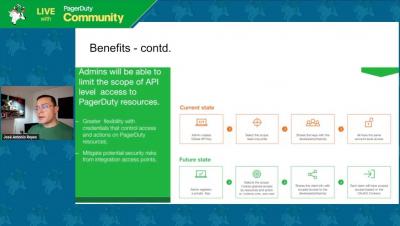
PagerDuty via Terraform - Intro to API Scopes
PagerDuty Innovation Software Engineer and Terraform Provider Maintainer José Antonio Reyes talks about improvements to the PagerDuty API with API Scopes and previews its implementation on PagerDuty’s Terraform Provider.