Ivanti Cloud: Data Services Demo: Momentum Vlog
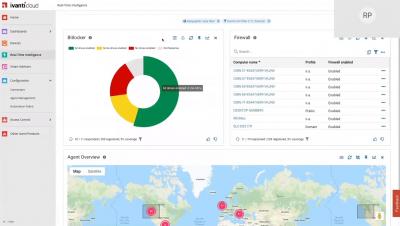
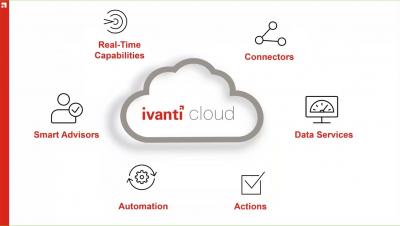
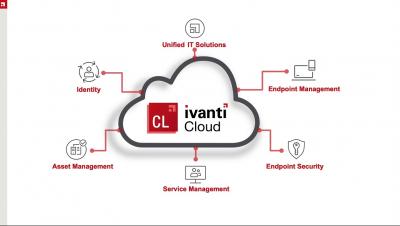
Quick take section from an Ivanti Momentum webinar about Ivanti Cloud. Provides information about the Data Services that is the engine for unifying data within Ivanti Cloud. Includes demos of how to set up Data Services, cloud agent, and connectors so organizations can get a clearer understanding of the IT data. Also includes demo for the Device View within Ivanti Cloud.