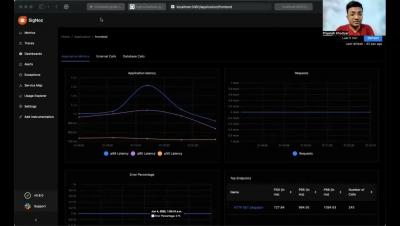
Configuring OpenTelemetry in Python
For this post, we’ll use a small Flask app that allows users to input a city name and they receive the current weather information for that city. We’ll make an API call to openweathermap.org to get the weather information for the city.