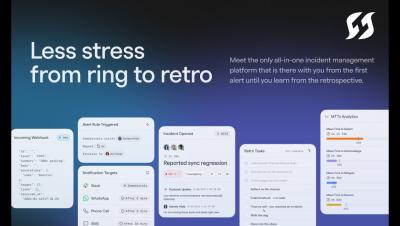
3 questions to ask of any DevOps tool in 2024
Is your DevOps tool stack out of control? I feel like every day, I talk to someone who feels this pain. The technological golden age of the past few years created a lot of niche tools, but now that CFOs and boards alike are demanding budget restraint, many of these tools are being scrutinized. The reality of the situation is that it’s not good enough for a tool to do one thing anymore.