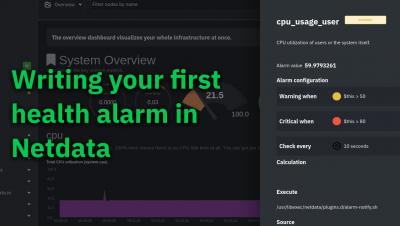
Start Kubernetes monitoring in 5 minutes with Netdata
While Kubernetes (k8s) might simplify the way you deploy, scale, and load-balance your applications, not all clusters come with "batteries included" when it comes to monitoring. Doubly so for a monitoring stack that helps you actively troubleshoot issues with your cluster. You need robust Kubernetes monitoring, but you don’t want to spend a week setting it up, much less a single valuable day.