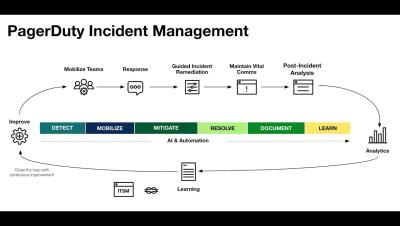
Not all incidents are created equal. How do you handle major incidents so that they don't spiral into a chaotic mess, incinerating productivity across too many teams? How do you prevent major incidents and learn from the ones you've had? "Major Incident Management" has been a practice for a long time, but as companies depend even more on digital services and revenue channels, while trying to do more with the same or less, something has to change.