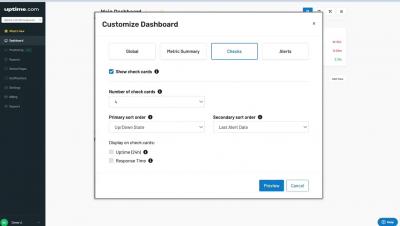
Performance Monitoring with API
If you are in a room with 20 engineers and you ask, “explain what an API is to a non-technical person”, you will get 20 different analogies. An API is like the on button to your TV connecting you to a variety of shows and systems, or an API is like a waiter taking your order and serving you from the kitchen. An API is like a library card catalog, or it’s simply a tool that connects you to other tools.