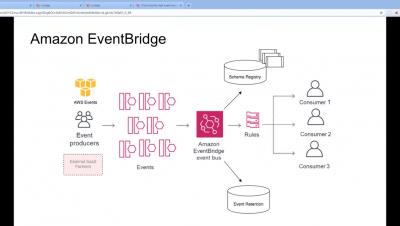
Webinar: Understanding Serverless Observability with AWS and Lumigo
Serverless experts from AWS and Lumigo go over how to add monitoring, logging, and distributed tracing to your serverless applications. Learn how to track serverless health metrics by getting visibility and alerts on specific serverless issues. Then troubleshoot using visual serverless maps, correlated AWS services, and logs to understand what service requires attention to keep high levels of application reliability.