Trace at Your Own Pace: Three Easy Ways to Get Started with Distributed Tracing
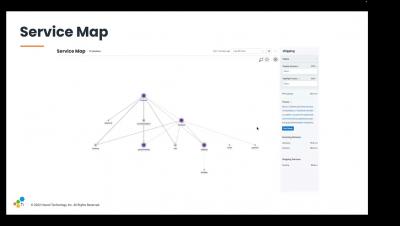
Stepping through a trace is an invaluable debugging workflow, providing a way to follow requests from service to service even as the applications we manage become more complex and distributed. That same complexity can make getting started with distributed tracing feel overwhelming, but it’s important to remember that instrumenting your code is an additive process—you don’t need to boil the ocean. A trace through a thousand services starts with a single ID.