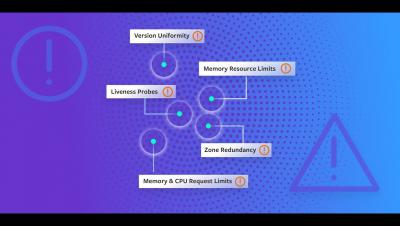
Introducing Detected Risks
We're excited to introduce a new enhancement to help teams build more reliable software: Detected Risks. Available today, Detected Risks helps you find and fix the most common causes of infrastructure outages and incidents in minutes—without running Chaos Engineering experiments or reliability tests.