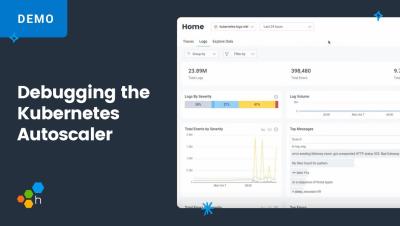
There's a new way to flip through your data in Honeycomb, released this week! It's super for looking at structured logs. It's called: Explore Data. Get directly at the logs, spans, events, or metrics that power the fast analysis you can do with Honeycomb. See all the fields, the whole variety of values — now ordered by timestamp, with pagination. Modify your query and graphs right from the data table. It's all connected!