Context Aware Events
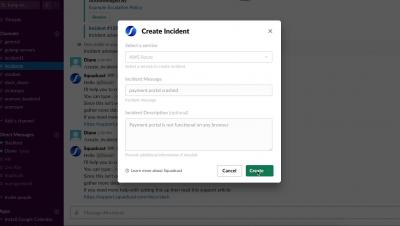
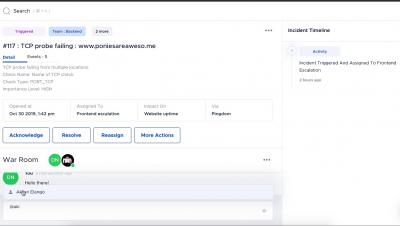
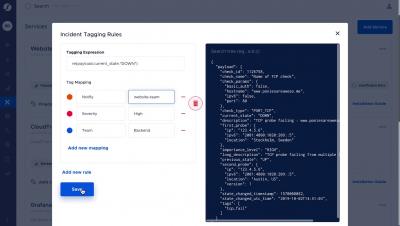
Squadcast is an incident management tool that’s purpose-built for SRE. Create a blameless culture by reducing the need for physical war rooms, centralize SLO dashboards, unify internal and external SLIs and automate incident resolution with Squadcast Actions and create a knowledge base to effectively handle incidents.