
Your Guide to Developing a Fail-Safe Incident Response Plan

Incidents happen. Every organization’s technical team will face an incident sooner or later, whether planned or unplanned.
An incident can be declared or initiated in response to an event or combination of events that affects the integrity or availability of a system or service in a way that impacts core business processes.
Incidents can range from minor software errors to complete service failures. An incident can be an entire data center outage, resulting from loss of power or a natural disaster. It can be a security incident, like a cyberattack, data leak, crypto lock virus, or other malware. Or, it can be something that is easy to miss yet produces a long-term negative impact, like a broken website form or slightly warm-running refrigerator.
Any incident has the potential to damage your operations or reputation. Imagine you manage a team for an internet service provider. Your customers rely on you for their home and business needs. If you are unable to provide a reliable service, they will turn elsewhere. To avoid this, an effective incident response strategy is vital.
Your incident response plan is an integral part of your organization’s broader incident management process. Think of it as the playbook containing all the necessary actions to take when an incident occurs. A fail-safe incident response plan is crucial to ensuring you can quickly mitigate and recover from incidents. Ultimately, you want to minimize each incident’s impact and damages, limiting the cost, shortening the recovery time, and protecting your organization’s reputation.
Incident response plans vary from organization to organization and from industry to industry, but they share some key characteristics. Let’s examine some important factors to think about when creating your plan.
Important incident response considerations
Ensure Timely Activation
An incident response plan is only as effective as its activation timeframe. The longer it takes to connect relevant team members and put measures in place to resolve the incident, the more critical the incident becomes. If it takes too long to execute the plan, what’s the point of even having the plan?
Not all incidents are created equal, however. A server failure or power outage may require urgent alerts and immediate action in the early hours of the morning. Other incidents may need resolution the next business day, or result in a low-priority ticket to make improvements when staff are available. Your plan should allow for different urgency levels, each with its own definition of “timely.”
Comprehensive service reliability platforms like xMatters help ensure timely activation. By monitoring data from many sources simultaneously, xMatters identifies issues, filters noise, and automatically activates your response plan.
Quickly Contact Responders
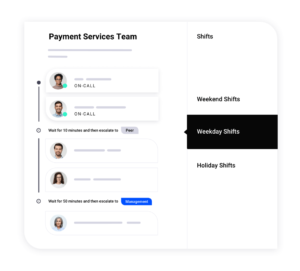
Your incident response plan must contain ways to quickly determine who’s on call to respond to each incident. These team members should receive a notification. Then, they can acknowledge the incident, confirm if they can work on it, and enter a chat or conference call with other relevant contacts. If they can’t work on it, the alert must be efficiently escalated to the next available resource.
Automating the process of notifying on-call responders optimizes incident response activation. Incident management platforms use detailed information to route the incident notification to the correct responder and include an option to escalate. Contacts can specify the best way to contact them, for example, on a specific device for a certain time of day.
Provide Consolidated, Contextual Information
We all know how important it is to have access to data to resolve an incident. However, too much information might mean that it takes more time to find the exact information you need.

A good incident response plan should ensure respondents can quickly access the consolidated, contextual information they need to diagnose and resolve an incident. An alert triggers the incident response plan, typically originating from a monitoring threshold. For example, if a system is down, the monitoring tool flags an event and sends a signal to the incident management platform, which then alerts responders. It’s also important to be able to handle a case where monitoring tools flag multiple events in a short period all related to the same incident, and to filter out redundant signals or notifications.
In addition to the primary alert information in their email, SMS, Slack, or other communications tool, the incident team should have access to additional helpful details, proactively pulled from other sources and available in a centralized place. One example is Kubernetes logs, which allow incident responders to see the order in which application pods crashed or stopped responding. Teams can also benefit from CI/CD logs — which help quickly determine whether a build was deployed shortly before the incident occurred — and even traffic logs from message queues such as RabbitMQ.
Not all contacts want or need all information, though. The site reliability engineering (SRE) team needs detailed technical information, while the COO just wants a call letting them know there is an outage. The incident response plan should recognize these different stakeholders, filter the noise, and provide the right information to the right people.
Options for Quick Resolution
Providing quick resolution options means shifting from detection and activation to execution and mitigation. This is the stage where organizations start to resolve incidents or find resolutions.
Ultimately, the incident plan should rely on automation as much as possible for faster resolution. Complex or multi-platform incidents require all hands on deck, but some common, recurring issues are easy to fix. Code can handle these.
Automation can quickly move your organization from detection to mitigation, often helping prevent an outage. For example, suppose an application or service outage occurs immediately after an updated continuous input (CI) build process, which triggered a deployment. An automated solution could suggest the incident respondents to perform a rollback to the last successful commit. You could set up the automation to initiate this process with a simple button click or even instruct the software to do it automatically without manual intervention or approval.
xMatters workflows are a great way to enable this kind of scenario. Step-by-step workflows offer a quick, one-click resolution to common incident causes, dramatically accelerating mean time to resolution (MTTR), and automating repetitive manual tasks.

Collect Data for Analysis
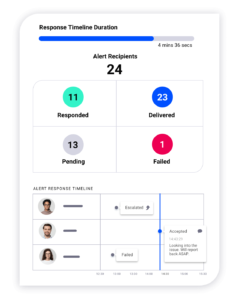
Your incident management tool should also collect relevant data while the incident is occurring, as we touched on earlier when we discussed ingesting data from multiple sources. You don’t just want log and monitoring data from the services that directly caused the incident. What if these services triggered the incident in response to a deeper problem in another service?
Ideally, you should be able to draw on data gathered across all of your integrated apps, services, and infrastructure, viewing one curated information source. This enables you to pinpoint incident root causes, perform a detailed postmortem, if applicable, and then determine next steps needed to prevent similar incidents from occurring in the future.
Automate Everything
Your incident response plan should activate quickly, notifying each relevant responder with tailored, consolidated, contextual information. It should provide quick resolution options and collect data for future analysis to help avoid similar issues. Doing all this manually would quickly turn into a disorganized mess, hindering your response. Now picture what this plan looks like when you combine these elements on a backbone of automation.
Automating your incident response helps you respond to and resolve incidents as quickly as possible. Noise filtering, information gathering, intelligent routing, and even part of the response itself happens smoothly without human intervention (or human error).
Automated incident response and management should lead you through the entire incident identification process, starting before the incident even occurs:
- Your incident management platform continuously checks information from your monitoring tools, determines if there are any anomalies, and ascertains their urgency.
- The incident occurs. Your solution detects this anomaly.
- This triggers an automated responder notification.
- Once the incident respondents acknowledge and accept the incident, the next automated process should run, collecting and consolidating data from affected systems.
- Based on recognizing the correct information from the data analysis, the necessary automated action occurs or responders can choose from a list of response options.
- Your incident is now resolved quickly, with little to no human intervention.
Automation is the key to making your incident response plan consistent, fail-safe, and fast.
Get Started Today
Creating a rock-solid, fail-safe incident response plan requires timely activation and quick notifications, and takes some work upfront, but it’s worth the effort to ensure you’re ready when an incident occurs. You need a tool that helps fight, mitigate, and reduce incidents before they cause problems for your business. There’s no one-size-fits-all incident response, but the features we discuss here should help you start creating the best plan for your needs.
The most critical requirement is that respondents can quickly determine what’s going wrong and when it started. However, if respondents lose time because they cannot find the correct information, or the correct person to help, your incident plan is missing its goal and is not fail-safe.
Manual tasks in the incident response process can lead to failures and typically slows response time. By working towards end-to-end automation, you can keep people focussed on solving the problem rather than figuring out the process.
If you’re ready to learn how to automate your incident response plan, why not schedule an xMatters demo today?