
Building AI Apps with AWS: From Foundation Models to Production-Grade Agents

Image Source: depositphotos.com
In the last two years, generative AI has moved from “cool demo” to become an integral element of IT production. The research proves this trend: according to Fortune Business Insights, global spend on generative AI reached an estimated $67 billion in 2024. By 2032, this spending is expected to pass almost $1 trillion, with a compound annual growth rate of approximately 40%. Moreover, a McKinsey & Company survey finds that roughly two-thirds of companies have already integrated generative AI into their workflows, and 80% use it in its broad sense. This technological transformation, hence, poses a critical new question: how do developers actually build, secure, and operate AI-driven systems at scale?
This article explains the transformation of a modern AI application stack on AWS. It covers model foundations, RAG systems, guardrails, and agentic architectures powered by Amazon Bedrock and the new AgentCore SDK.
1. Foundational models as the new “runtime”
Foundational models (FMs), which are large neural networks trained on massive text, image, or audio corpora, have become the new “runtime” for AI systems. There are three main classes of such:
- Large language models (LLMs): text and code (Claude, Llama, Mistral);
- Vision models: images and multimodal understanding;
- Audio models: speech-to-text.
Amazon Bedrock: serverless access to FMs
AWS Bedrock encapsulates this complexity, including infrastructure management and scaling, within a serverless multi-model API. For instance, it is now possible to call models from Anthropic (Claude), AWS Titan, Meta LLama, Mistral, and newer Nova models without managing GPUs, autoscaling, or deploying pipelines. A developer would see the following information:
- Invoking invoke_model / invoke_model_with_response_stream to send prompts and stream responses.
- Text, chat, and embedding operations are exposed via the same control page.
- Cross-region inference is possible but introduces latency. Hence, co-locating data and inference remains the best practice for building AI applications.

Figure 1. Amazon Bedrock inference: synchronous vs. streaming invocation.
The model-as-a-service pattern mentioned above exemplifies the industry transformation: analysts describe AI entering its platform-as-a-service (PaaS) phase, in which vendors provide platforms for agents, RAG, and guardrails, rather than just raw GPUs.
Prompting is the new API
The prompt structure is now part of the application contracts that define how these applications interpret inputs and orchestrate downstream components. To establish effective patterns, it is important to assign roles (“You are a customer-support assistant”), provide context (retrieved documents and system constraints), and specify constraints (tone, format, allowed tools, and maximum cost). When more developers consider prompts like code - that is, versioned, tested, and reviewed - Bedrock’s interface, in turn, improves its stability layer where those prompts execute.
2. Safety and security
Generative AI is an effective tool in many contexts, yet concerns about its unfounded models raise compliance risks. As such, regulators and auditors expect explainable policies for AI outputs. Compliance needs to ensure that issues such as harmful content, accidental exposure of sensitive data, and uncontrolled prompts entering logs or third-party services are addressed. AWS ensured compliance with Guardrails for Amazon Bedrock and Amazon Comprehend.
These guardrails are mapped to four layers of the stack - model inference, agents, knowledge bases, and flows. They help developers filter or rewrite incoming prompts, block or adjust model outputs, and apply the same policies to different agents and knowledge bases.
Comprehend for PII detection and redaction
Amazon Comprehend adds PII detection at both the pre- and post-processing stages, so that sensitive data is masked or removed before model invocation, during dataset preparation, before knowledge-base indexing, and within logs and analytics. When applying guardrails during data ingestion, developers also ensure that RAG knowledge bases are sanitised upfront and do not store sensitive information. However, safety alone is insufficient without reliable access to up-to-date data.
3. RAG: From static models to enterprise knowledge
Fine-tuning is often used as the default approach for injecting domain knowledge into models. In real life, however, this process is expensive and slow. The table below compares it to Retrieval-Augmented Generation (RAG):
|
Fine-tuning |
RAG |
|
The model is trained on new data |
Model remains unchanged but is enriched with context |
|
Personalized domain |
The relevance of data is critical |
|
Requires retraining for every knowledge update |
Search through documentation |
|
Requires extensive testing |
Fast document updates via vector database |
|
Accuracy may be higher |
Lower cost: indexing + retrieval |
|
Expensive GPU usage |
Infrastructure: vector storage |
|
Risk of overfitting |
Reduced risk of overfitting |
|
Requires strong ML expertise and infrastructure |
Requires retrieval and data engineering skills |
|
Data preparation can take weeks |
Data ingestion and updates are relatively fast |
Fine-tuning requires new training for every knowledge update and meticulous data preparation. On the other hand, RAG keeps the base model frozen and enriches it with retrieved context at query time. According to RAGFlow, these features made RAG the dominant architecture for grounding LLMs in enterprise data and reducing hallucinations.
Below, the basic RAG loop is illustrated:
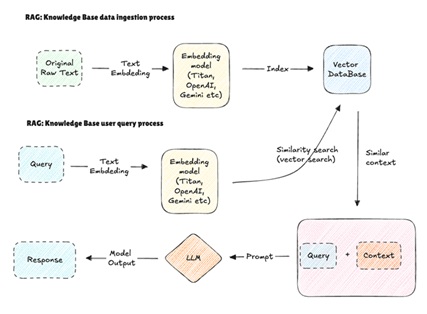
Figure 2. Multimodal RAG: text and image retrieval with vector search.
The process includes user query, retrieving relevant chunks from a knowledge base, feeding the query and the chunks into the LLM, and generating outputs with citations. There is a higher-level data flow, as well. It consists of the following steps: document, chunking, embeddings, vector DB, query embedding, nearest-neighbour search, ranked chunks, and LLM.
For achieving the best results with RAG, these tips would be beneficial:
- Tune the chunk size to balance context retention and retrieval precision.
- Store original text alongside embeddings to quickly assemble prompts.
- Use metadata filters (tenant, product, language, security tags) in your vector DB.
AWS flavours of RAG: OpenSearch vs. Kendra
At AWS, RAG can operate on multiple services, including OpenSearch and Kendra. (Recently AWS introduced s3 vectors, which provides new opportunities for RAG but its not covered in the paper). The former is ideal when you need low-level control or multi-tenant logic, and you handle embeddings (for example, Titan) and document chunking yourself. The latter is suitable for enterprise search with less infrastructure overhead. Amazon Kendra manages vector storage where for example S3 can serve as data source. Also there are connectors (Quip, Slack), so developers do not need to implement custom parsers. Afterwards, Bedrock uses Kendra’s semantic search results as context for models such as Claude.
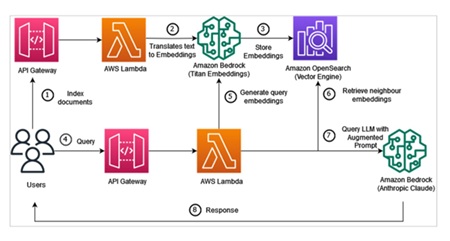
Figure 3. AWS RAG pipeline with Bedrock and OpenSearch.
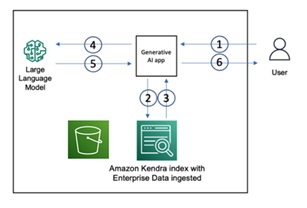
Figure 4. RAG with Amazon Kendra and enterprise data.
Hence, the trade-off is clear: OpenSearch gives developers knobs, while Kendra provides a higher-level search interface with less operational overhead.
RAG’s observability and evaluation
RAG requires continuous monitoring, especially for accuracy control. This includes using dedicated libraries such as RAGAS (an LLM used as a judge under the hood), alongside custom evaluation datasets, to systematically assess system performance and ensure outputs are grounded in the source material. The most important metrics to track are retrieval hit rate, context relevance, answer faithfulness, and hallucination rate.
The example below shows metrics such as answer faithfulness, context relevance, and answer similarity, visualised with distributions of “good” vs “problematic” queries.
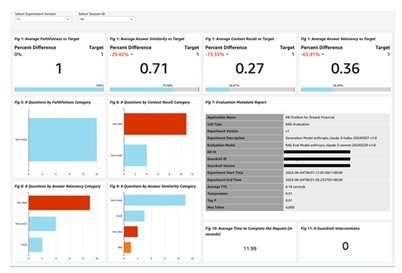
Figure 5. RAG evaluation and quality monitoring dashboard. Other boards can be found on AWS GitHub.
When working with RAG, Ops teams need to adopt a mindset that prioritises prompt and retrieval-based quality in new Service Learning Objectives (SLOs), not art projects.
From chatbots to agents: orchestrating work
Once reliability is achieved, the next step is to have them take action - this is the moment when AI agents come in.
Once your models can reliably answer questions, the next step is to have them take actions. This is where AI agents come in. This article defines them as software systems that interact with their environment, gather data, and independently take actions to achieve human-defined goals.
AI agents are at the peak of their popularity in the industry. For instance, McKinsey’s 2025 survey found that 23% of organisations are already scaling agentic AI systems, and another 39% experimenting. According to Kanerica Inc., by 2030, up to 60% of companies’ workflows will be managed by agents.
ReAct: reasoning + action loops
AWS employs the ReAct (Reason + Act) patterns, which provide a structured approach to agent behaviour by executing an interactive cycle of reasoning and action. These cycles begin with a Question, representing the user request, followed by a Thought in which the model generates a reasoning step to determine the following action. The Action refers to invoking an external tool, such as an API or database query, and the resulting Observation captures the tool’s output.
This is a troubleshooting example with ReAct:
User query: “I can’t access Dashboard A.”
Thought (reasoning call): Check whether the user has access to Dashboard A.
Action 1:GetUserAccessRights(user_id, "Dashboard A")
Observation 1: User has access to Dashboard A.
Thought: Access is valid. Next, check whether Dashboard A is up.
Action 2:CheckServiceStatus("Dashboard A")
Observation 2: Service is operational.
Thought: Access and service are fine. Check recent login attempts.
Action 3:GetAccessLogs(user_id, "Dashboard A")
Observation 3: Access is blocked from the external network.
Final answer: Your access to Dashboard A was blocked due to external network restrictions. Please connect via VPN or the corporate network.
In total, there is one initial reasoning call, three action-observation loops, and one final answer - five LLM calls. This pattern, in which multiple short model calls are orchestrated by tools, is typical of agents.
4. Bedrock Agents: managed orchestration
While the ReAct pattern defines how agents interleave reasoning and action at a conceptual level, Bedrock Agents operationalise this logic at an orchestration layer.
The orchestration process with Bedrock Agents includes the following steps:
- Selecting a foundation model.
- Defining the agent’s instructions and profile.
- Attaching data sources (knowledge bases, APIs).
- Configuring action groups backed by AWS Lambda.
Within this architecture, AWS Lambda serves as the execution layer for actions. It implements domain-specific business logic, integrates with internal systems, and invokes external services. At the same time, Amazon Bedrock is responsible for controlling aspects of the agent, such as intent understanding, deciding which action group to invoke, or managing the iterative loop of thoughts, actions, and observations.
This separation of concerns is another market trend: major companies are aiming to provide agent platforms. A notable example is Salesforce’s Agenforce, with already over $500M in ARR.
Return of control: designing for long-running work
One practical consequence of this shift is the need to handle long-running workflows. Agent interactions often exceed standard API timeouts, especially when involving multiple tool calls, external systems, or asynchronous processes. To address the issue, agent platforms introduce mechanisms to pause and resume execution. In the context of Bedrock Agents, these mechanisms are based on Return of Control, which allows execution to be handed back to the application. Meanwhile, the agent waits for longer-running tasks to complete.
For Ops teams, this process might resemble working with distributed teams: they must handle timeouts, idempotence, and partial failures across agents and tools.
Traces and logging
The example code block is a JSON example with an agent calling a weather API.
"trace": [
{
"traceType": "OrchestrationTrace",
"orchestrationTrace": {
"inputText": "What's the weather in Paris?",
"invokedActions": [
{
"actionGroup": "WeatherAPI",
"function": "getWeather",
"parameters": [
{ "name": "location", "value": "Paris" }
],
"result": {
"responseBody": {
"temp": "18°C",
"condition": "Sunny"
}
}
}
],
"knowledgeBaseQueries": [],
"nextStep": "Return answer to user"
}
}
]This log gives developers a complete picture of each agent decision, visibility into which tools were called with which parameters, and the ability to debug and tune orchestration.
5. AgentCore SDK: Bedrock as a True Agent PaaS
The most recent addition to the Bedrock ecosystem is Amazon Bedrock AgentCore, which introduces a code-first approach to building agents and allows developers to define agent logic in Python and expose callable tools through function decorators. Its deployment is managed with the agentcore launch command. This command packages the code into a container, pushes it to Amazon ECR, deploys a runtime, and exposes an invocation endpoint. This approach provides a PaaS experience for agent development.
Operational control, on the other hand, is handled through the control plane using Boto3. The system allows developers to manage runtimes and tools and invoke built-in capabilities, such as code interpreters or browser sandboxes.
The code-first approach improves on the earlier UI/CDK and Boto3 model by consolidating agent logic into a single Python codebase while retaining versioning, aliases, and control over IAM and VPC settings. Recent industry benchmarks from Constellation Research report 15–24× time savings compared to DIY implementations. This result indicates that the PaaS layer is becoming a competitive advantage for companies.
6. CDK vs SDK: Who owns what in the stack?
Here we should probably explain AWS infrastructure specifics such as CDK. The distinction between infrastructure-as-code tools, such as AWS CDK, and AWS SDKs is important for AWS projects growing in complexity. AWS CDK is Amazon’s infrastructure-as-code framework, defining and deploying cloud resources (environments, permissions, networking, pipelines), while SDKs (such as Boto3 or the AWS JavaScript SDK) interact with these resources. The actions include, for example, uploading documents or orchestrating workflows. For developers, maintaining this separation is beneficial since CDK stacks and pipelines impact the underlying AI platform in terms of environments, permissions, and networking. In turn, application code relies on SDKs to feed data, call models, and coordinate agent behaviour.
It is now apparent that high-performing developer teams treat foundation models as first-class agents, applying the same operational discipline as for Kubernetes clusters or message queues.
7. Practical Recommendations for Ops and Platform Teams
Bringing this article together, here are the steps for building AI apps on AWS today:
-
Standardise the foundation model layer. Use Amazon Bedrock as a multi-model abstraction to reduce vendor lock-in, starting with managed models and considering custom training only when ROI is clear.
- Default to RAG. Implement RAG before fine-tuning, using Kendra for low-ops enterprise search and OpenSearch for more efficient control.
- Build safety in by design. Apply Guardrails for prompts, agents, and knowledge bases, and use Comprehend for PII detection and redaction.
- Instrument from day one. Monitor retrieval quality, capture agent traces, and regularly evaluate outputs for faithfulness and relevance.
- Use AgentCore for complex workflows. Apply AgentCore for multi-step orchestration, keep tools small, and use return-of-control for long-running tasks.
- Design for flexibility. Treat AI as a multi-vendor ecosystem.
Closing thoughts
Nowadays, LLMs, RAG, guardrails, and agents form a standard application stack, similar to databases and message queues in earlier periods of software development. For developers, it is crucial to treat these models as secure services, grounding them in enterprise data through RAG, and to apply observability and infrastructure-as-code by default. As large-scale production gains popularity, operational excellence will become the primary business advantage. Moreover, developers who master agent orchestration and platform patterns on AWS will define how agentic AI is deployed reliably at scale.