Why observability is the way to go w/ Georg Höllebauer (APA-Tech) | The StackPod EP #2
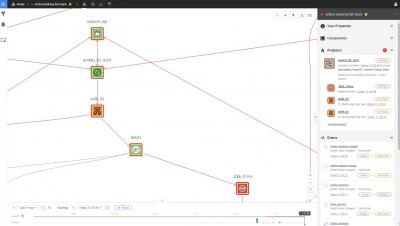
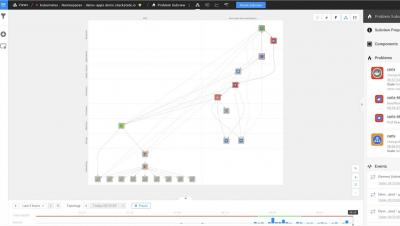
Welcome to the second episode of the StackPod! For the second episode, we invited Georg Höllebauer. Georg is an enterprise metrics architect at APA-Tech. APA-Tech is responsible for all IT services within the Austrian Press Agency - Austria's national and largest press agency - and other customers.