

|
By AlertOps
Two weeks after a payments outage took a regional bank offline for ninety-three minutes, the post-incident report landed on the CIO’s desk. It ran forty pages. It named the failed service, the ticket numbers, the restoration steps, and the engineers who paged in. It did not answer the question the board had actually asked, which was why the on-call team had spent the first forty-one minutes chasing a downstream symptom rather than the upstream cause.

|
By AlertOps
Why Fixing Incidents Is Only Half the Work Fixing an incident is not the same as solving a problem. In enterprise IT operations, that distinction carries significant operational weight. Organizations that treat every disruption as a discrete, isolated event to be resolved and closed will continue to encounter the same disruptions, on the same infrastructure, from the same root causes. The cycle does not end because the underlying problem was never addressed.

Jira Notifications Management: The Enterprise Guide to Routing, Reducing Noise, and Closing the Loop
|
By AlertOps
Jira is the system of record for engineering work at nearly every enterprise that runs agile delivery. It tracks epics, stories, bugs, sprints, releases, and the long tail of technical debt that keeps platform teams awake. What Jira was never designed to be is an alerting system.

|
By AlertOps
Why Confusing Them Costs You More Than a Missed Target Every operations leader tracks KPIs. Every enterprise IT team has SLAs. Both involve targets, both involve measurement, and both surface in the same board reviews and vendor conversations. So it is not surprising that the two get treated as variations of the same thing.

|
By AlertOps
A Practical Guide for Help Desk, IT Operations, and Enterprise SRE Teams A service level agreement template is only useful if it can be customized. The version that ships with your ITSM platform was designed to be generic enough to apply anywhere, which makes it precise enough to apply nowhere. The teams that maintain defensible SLAs are not the ones with the most sophisticated legal language.

|
By AlertOps
How to Draft, Customize, and Keep Service Level Agreements Defensible Most enterprises do not discover the weaknesses in their SLAs during the drafting process. They discover them during an incident review, a customer escalation, or a contract dispute, when the language that seemed reasonable at signing turns out to be too vague to measure, too broad to enforce, or disconnected from the operational data that would make it defensible.

|
By AlertOps
The incident is over. The service is back up. The monitoring dashboard is green, the on-call engineer has stood down, and the post-incident review is on the calendar for Thursday. But there is a question that separates good operations teams from great ones: do you actually know what that incident cost you in terms of reliability commitments? Whether you breached an SLO. Whether a customer-facing SLA is now at risk.

|
By AlertOps
Why enterprise operations teams stop chasing incidents and start preventing them Most enterprise operations teams are faster than they were three years ago. Alert routing is automated. On-call schedules are managed through platforms rather than spreadsheets. MTTR has come down as tooling has improved. On the metrics that measure reactive performance, progress is visible. What has not meaningfully changed is the rate at which the same incidents recur.

|
By AlertOps
A complete guide to modern incident management and how it’s transforming into a strategic business function. Kamalesh Srikanth , Product Strategy Leader at AlertOps If you’ve worked in IT, infrastructure, or operations for any length of time, you’ve lived through the chaos of a critical incident. Systems down, alerts blaring, Slack pinging, emails piling up and somewhere in that noise, your team is trying to figure out what actually broke and how to fix it fast.

|
By AlertOps
Here’s a scenario most IT teams know too well: a single error message lights up the monitoring dashboard at 2 a.m. Within seconds, calls are coming in from customers. Within minutes, the revenue meter is running. If your team is still figuring out who owns the incident while that meter ticks, you’ve already lost precious time. According to 2024 EMA Research, unplanned IT downtime now costs organizations an average of $14,056 per minute, rising to $23,750 per minute for large enterprises.


|
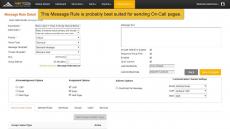
By AlertOps
Send to one user at a time, then retry 5 times at 5 minute intervals before escalating to the next user. You can change the intervals and timings.
|
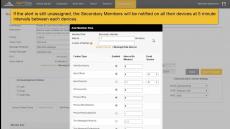
By AlertOps
Notifies one device at a time for each user before escalating to the next user. Each user defines their own notification sequence in their user profile.



|
By AlertOps
This guide provides best practices and practical guidelines for the management of network operations and information security incidents. Incidents happen, and cost organizations thousands of dollars due to downtime.
|
By AlertOps
Development and operations (DevOps) empowers organizations to deliver applications, products and services faster and more efficiently than ever before. The DevOps model unifies development and IT operations (ITOps) teams for more efficient achievement of your company's business objectives.
- May 2026 (6)
- April 2026 (2)
- March 2026 (2)
- November 2025 (3)
- October 2025 (3)
- March 2025 (2)
- September 2024 (1)
- June 2024 (2)
- May 2024 (3)
- January 2024 (3)
- August 2023 (2)
- June 2023 (1)
- April 2023 (1)
- March 2023 (2)
- February 2023 (1)
- October 2022 (2)
- August 2022 (1)
- July 2022 (3)
- June 2022 (1)
- May 2022 (2)
- April 2022 (1)
- February 2022 (2)
- January 2022 (3)
- December 2021 (1)
- November 2021 (1)
- October 2021 (2)
- September 2021 (1)
- August 2021 (1)
- June 2021 (2)
- May 2021 (1)
- March 2021 (3)
- February 2021 (7)
- January 2021 (5)
- December 2020 (4)
- November 2020 (2)
- October 2020 (2)
- September 2020 (1)
- August 2020 (3)
- July 2020 (3)
- May 2020 (1)
- April 2020 (2)
- March 2020 (1)
- January 2020 (1)
- August 2019 (1)
- July 2019 (4)
- May 2019 (1)
- April 2019 (1)
- December 2018 (1)
- October 2018 (1)
- September 2018 (2)
- August 2018 (1)
- July 2018 (5)
- June 2018 (1)
- May 2018 (3)
- April 2018 (1)
- February 2018 (1)
- January 2018 (1)
- December 2017 (1)
- November 2017 (1)
- September 2016 (2)
- May 2016 (3)
- July 2015 (4)
AlertOps is a collaborative incident management solution that integrates multi-modal communication, application monitoring, change management and SLAs. It helps IT Operations manage and optimize their alerts from various monitoring systems to greatly reduce Alert Fatigue and Mean Time To Resolution (MTTR).
Mobilize all your teams to take immediate and unique action, simultaneously:
- Manage Major Incidents - Together: Notify all your key teams, managers, and stakeholders, based on severity levels, schedules, skillsets and more.
- Work Fast, with Workflows: Automate your DevOps toolchain and build workflows that streamline delivery processes and improve real-time collaboration.
- Protect Customer Experiences: Escalate incidents, and keep stakeholders in the loop with uniquely relevant messages to provide excellent customer experiences.
Give your teams the un-matched power and flexibility they need to manage major incidents and protect business-critical services.