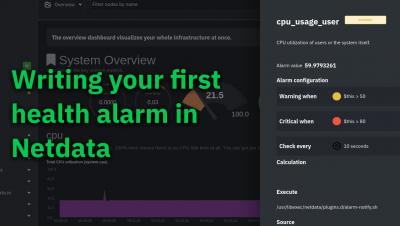
Actionable alerts with fewer false positives: intelligent alarms with Netdata
Think about any sport or competitive activity, whether that’s football or a spelling bee. They always feature at least one person who acts as a moderator, referee, or judge. With their domain expertise, this person watches everyone’s behavior and constantly compares that against a set of rules. If someone crosses that threshold, they blow a whistle or throw up a flag. They are, in effect, saying that things have gone from OK to not OK.