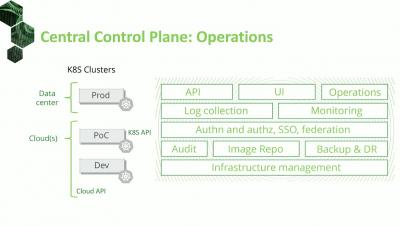
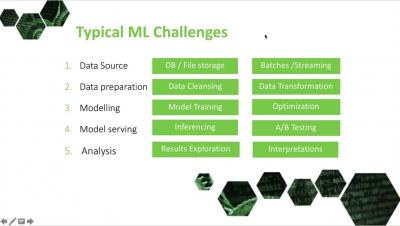
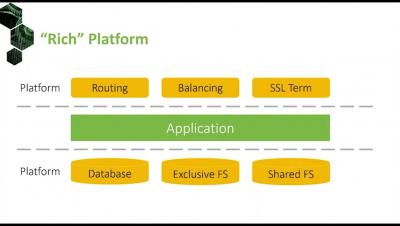
Setting up a CI/CD pipeline with Jenkins, Nexus, and Kubernetes
This is the first in a series of tutorials on setting up a secure production-grade CI/CD pipeline. We’ll use Kublr to manage our Kubernetes cluster, Jenkins, Nexus, and your cloud provider of choice or a co-located provider with bare metal servers. A common goal of SRE and DevOps practitioners is to enable development and QA teams. We developed a list of tools and best practices that will allow them to iterate quickly, get instant feedback on their builds and failures, and experiment.