
Site Reliability Engineering: Definition, Principles & How It Differs From DevOps

Site crashes and outages can cost hundreds of thousands in lost revenue and inconvenience users. Site Reliability Engineering helps build highly reliable and scalable systems, particularly important for companies that depend on their software to support their customers performing critical operations.
Hiring a Site Reliability Engineer is the best way to ensure a software system stays up and running at all times. Not only will they help manage infrastructure and applications, but they’ll also be able to advise on how to scale a business as it grows — keeping downtime and incidents at a minimum!
This blog post will explain what Site Reliability Engineering means, its principles and practices, and how it differs from DevOps.
What is Site Reliability Engineering?
Site reliability engineering (SRE) is an approach to IT operations based on software engineering. SRE teams employ software to manage systems, address problems, and automate processes. The practice transfers duties formerly performed by operations teams, sometimes manually, to engineers.
Google’s VP of Engineering, Ben Treynor Sloss, created the term in 2003. The best way to describe the concept in a sentence is on his LinkedIn profile page: “tl;dr: If Google ever stops working, it’s my fault.”
Following its inception at Google, the notion expanded throughout the software development industry, and other organizations began to employ Site Reliability Engineers (SREs) as a result.
As a job role, SRE can be performed by a single practitioner or by teams typically in charge of a combination of the following within a larger engineering organization:
- System availability
- Change management
- Monitoring
- Emergency response
- Capacity planning
The role is more typical in bigger online organizations, as small businesses seldom operate at the size that would necessitate specialized SREs.
The Role of Site Reliability Engineers
Software engineers, system engineers, and system administrators are common backgrounds for SREs.
SREs spend no more than half of their time performing manual IT operations and system administration tasks — such as analyzing logs, tuning performance, applying patches, testing production environments, responding to incidents, and conducting postmortems — and the other half developing code that automates those tasks.
Today’s SREs understand how to balance. Most of them are balancing their work between operations and development, with a 20% median value of time spent in operations and 40% percent median value of time spent exclusively on development, according to Catchpoint’s 2021 SRE Report.
One of the primary duties of SREs is to assist teams in determining when and what new features may be released by utilizing Service-Level Agreements (SLA), dependability through Service-Level Indicators (SLI), and Service-Level Objectives (SLO).
SLOs define the specifications of a measure within an SLA, such as service uptime or response time, which are the objectives that the service team must achieve. An SLO is often a numerical target for the service indicated in the SLA that the SREs define. For example, “application availability will be 99.95% of the time during any given 24-hour period.”
Risk-takers, tinkerers, and innovators are descriptors of great SREs. They determine what it takes to grow a system from 100 to 100,000 to 1,000,000 users while retaining availability and resilience. They are systems thinkers who analyze how development decisions affect production settings and how production system demands might influence design.
SRE Principles and Practices
There have been several attempts to define a canonical list of SRE principles. However, while an agreement is absent, the following features are often included in most such definitions.
Automation
Anything repetitious that is also cost-effective to automate or remove should be automated or eliminated.
The underlying idea of SRE is that employing software code to automate supervision of large software systems is a more scalable and sustainable technique than manual involvement, particularly when such systems expand or relocate to the cloud.
Engineers responsible for site reliability should continually search for improving and automating operational chores.
Risk management
Systems should be designed to maximize availability and efficiency, meanwhile minimizing latency. SRE assists teams in striking a balance between launching new features and ensuring their reliability. As a result, SRE helps to increase a system’s reliability now while also enhancing it over time.
Observability
SREs improve service health visibility by recording metrics, logs, and traces across all services in the company and giving context for determining root causes in the case of an issue.
Requirements and metrics definition
SREs help development and operations teams comprehend the cost of SLA breaches and estimate the impact of system reliability on production, sales, marketing, customer support, and other business processes to quantify the cost of downtime.
Monitoring and alerting
Another critical principle of SRE is to build efficient on-call operations and streamline alerting workflows to improve problem response.
Today, the best SRE teams construct state-of-the-art operations centers by integrating in-depth knowledge of IT operations with AI to deliver warnings straight to the person in charge of resolving the issue.
Site Reliability Engineers vs. DevOps
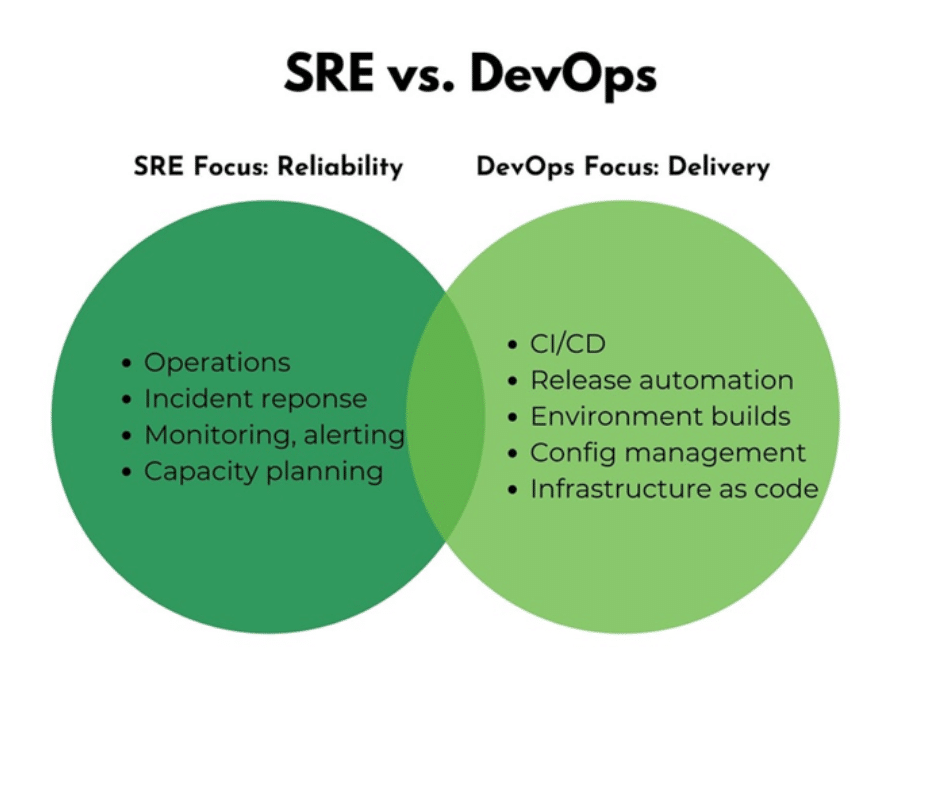
People and processes are at the core of SRE, and it’s the bridge between platform design, development, and operational execution, which requires SREs to shift left to share production wisdom with those teams delivering value-added products and services to that production environment.
The central SRE mantra aims to “automate everything” to give people the best chance of focusing on meaningful activities. Therefore, the goal of automation for SREs is less about deploying code or releases as quickly as possible and more about providing value to customers through a risk-reducing, scalable approach.
SRE has also been defined as a specialized application of DevOps. However, it focuses on constructing reliable systems rather than infrastructure in general, whereas DevOps is more widely focused on infrastructure.
The main difference is that DevOps focuses on swiftly moving through the development pipeline in code and new features, whereas SRE focuses on balancing site dependability with new features.
As a result, while not technically necessary for DevOps, SRE strongly correlates with DevOps concepts and may play an essential part in DevOps success.
At MoovingON, we can help you secure availability, income, and a positive client experience. We provide SRE-as-a-service to enable proactive monitoring and remediation, assuring your business’s uptime 24 hours a day, seven days a week.