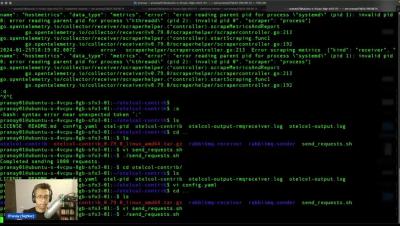
Soft Min and Max Axis Limits for Charts
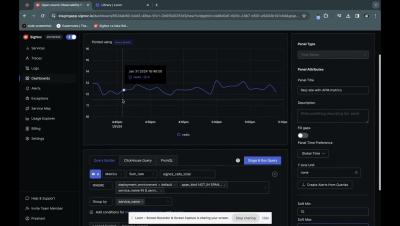
With soft min and max axis limits, the axis will not shrink down to show smaller variation in data as large mountains. So while creating charts you can specifiy a min and a max value for your axis. Actual datapoints will have the highest preference, so you won’t be able to set a min lower than an actual datapoint in your chart.