Custom Alerts Using Prometheus in Rancher
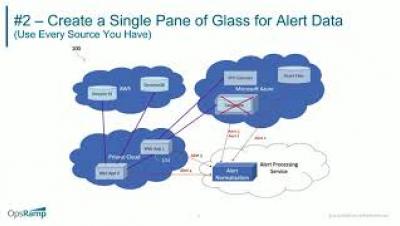
This article is a follow up to Custom Alerts Using Prometheus Queries. In this post, we will also demo installing Prometheus and configuring Alertmanager to send emails when alerts are fired, but in a much simpler way – using Rancher all the way through. We’ll see how easy it is to accomplish this without the dependencies used in previous article.