The Future of Database Monitoring - AIOps
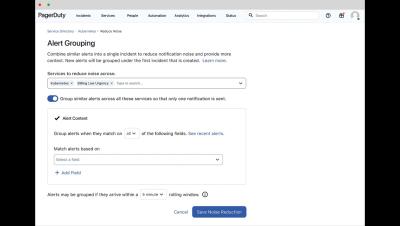
IT pros need tools designed to ingest large volumes of data, correlate events across data sources, detect problems, and resolve them with new technologies to support more efficient IT systems. This is the function of AIOps. AIOps or Artificial Intelligence for IT Operations, is the use of artificial intelligence (AI) and machine learning (ML) technologies to enhance and automate various aspects of IT.