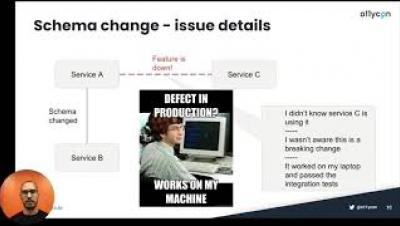
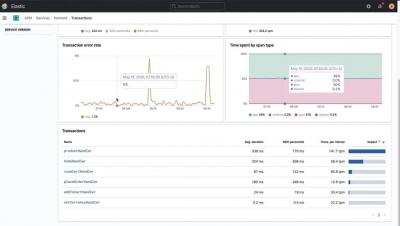
Tracing the Path to Clear Visibility in DevOps
Today, we’re excited to announce enhancements to the VMware Tanzu Observability by Wavefront platform, which helps teams scale their observability practices and shorten the feedback loops between development and operations. The new features give more flexibility and functionality to any open source investments; help operations, development, and SRE teams resolve problems faster; and extend observability more efficiently into DevOps workflows. Here’s a quick rundown of what’s new.