Sponsored Post

Classifying Severity Levels for Your Organization
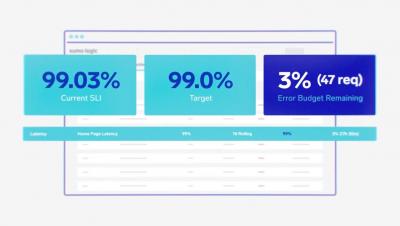
Major outages are bound to occur in even the most well-maintained infrastructure and systems. Being able to quickly classify the severity level also allows your on-call team to respond more effectively. Imagine a scenario where your on-call team is getting critical alerts every 15 minutes, user complaints are piling up on social media, and since your platform is inoperative revenue losses are mounting every minute. How do you go about getting your application back on track? This is where understanding incident severity and priority can be invaluable. In this blog we look at severity levels and how they can improve your incident response process.